No último post baixamos e carregamos os dados para o PostgreSQL, hoje iremos dar sequencia no artigo, configurando a pesquisa Full-text.
A fim de fazer um mapa eficiente, temos que encontrar rapidamente os registros que têm as palavras que estamos interessados. Felizmente, o PostgreSQL fornece a facilidade de uma pesquisa de texto completo (full-text search) para a procura rápida e eficaz dos campos texto. Com ela é possível combinar automaticamente palavras diferentes-mas-semelhante (como “árvore” e “árvores”) e encontrar palavras particulares em grandes blocos de texto.
Nossos dados não são particularmente pesados (a maioria dos nomes de lugares na nossa base de dados consistem em apenas duas palavras, apenas alguns têm três ou mais), mas full-text search ainda será mais eficiente do que uma simples correspondência de padrão, porque ele pode fazer uso do índice full-text.
O full-text faz uso de tipos do PostgreSQL especializadas: tsvector e tsquery.
Ele depende da criação de um índice no tsvector representando um (ou vários) campo de texto. Podemos ver o efeito do índice, executando uma consulta de teste antes e depois de construí-lo.
-- Watch the timing of this query
SELECT Count(*) FROM geonames WHERE to_tsvector('english', name) @@ to_tsquery('english', 'oak');
-- Create the full-text index
CREATE INDEX geonames_fulltext_idx ON geonames USING GIN (to_tsvector('english', name));
-- Again, watch the timing of this query
SELECT Count(*) FROM geonames WHERE to_tsvector('english', name) @@ to_tsquery('english', 'oak');
Quando o nosso aplicativo envia de volta o texto a partir da interface web, o texto pode conter espaços. A função to_tsquery () não gosta de espaços, ela espera que cada palavra na string de consulta devem ser separados por “&”, “AND”, “|” ou “OR”.
Para resolver este problema e retirar qualquer espaço à na palavra, vamos usar a função trim().
-- Example of space trimming
SELECT trim(' New York ');
A seguir, vamos tratar todo o texto com espaços como consultas. Por isso, queremos substituir os espaços entre as palavras com o símbolo “&”.
-- Example of trimming and turning spaces into &s
SELECT regexp_replace(trim(' New York '), E'\\s+', '&', 'g');
Finalmente, podemos colocar o resultado em um to_tsquery() executando na query atual.
-- Again, watch the timing of this query
SELECT Count(*)
FROM geonames
WHERE
to_tsvector('english', name) @@
to_tsquery('english', regexp_replace(trim(' New York '), E'\\s+', '&', 'g'));
Agora, imagine que “New York” poderia ser substituído por qualquer palavra que você quisesse, e que os resultados poderiam ser colocados em um mapa em tempo real! Isso é o que nós vamos configurar a seguir.
Para este artigo, vou considerar que o GeoServer está configurado com as camadas (em uma store PostGIS) e você criou um workspace com o nome “wordmap”.
Tendo dito isto, vamos configurar a nossa camada SQL View, indo na opção “Add Layer”.
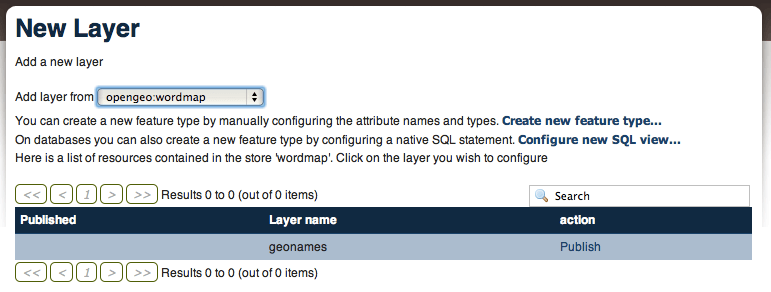
Vamos setar o nome da nossa camada como geonames, com o SQL a seguir:
SELECT id, name, geom
FROM geonames
WHERE
to_tsvector('english', name) @@
to_tsquery('english', regexp_replace(trim('%word%'), E'\\s+', '&', 'g'))
Esta é basicamente a mesma consulta usada na seção anterior. Ela rapidamente encontra todos os registros em que o nome contém uma palavra particular. Neste caso, em vez de procurar por uma palavra particular, nós colocamos %word% como um parâmetro. Isso nos permite buscar qualquer palavra, apenas passando o parâmetro na URL.
Esta é basicamente a mesma consulta usada na seção anterior. Ela rapidamente encontra todos os registros em que o nome contém uma palavra particular. Neste caso, em vez de procurar por uma palavra particular, nós colocamos %word% como um parâmetro. Isso nos permite buscar qualquer palavra consulta do GeoServer, apenas passando o parâmetro na URL.
Depois de criar a SQL View, vá até a seção “SQL view parameters” e clique em “Guess parameters from SQL”:
– O parâmetro “word” deve estar preenchido na lista de parâmetros.
– Defina o valor padrão para “oceano”.
– Defina a “validação de expressão regular” para “^ [\ w \ d \ s] * $”
*Esta expressão permite apenas letras, números e espaços, incluindo os valores vazios.

Agora vá para seção “Attributes” e clique em “Refresh”. As colunas “id”, “nome” e “geom” devem ter sido inferidas a partir do SQL.
– Verifique se “id” está como identificador exclusivo.
– Defina o campo “geom” como ponto .
– Defina o “SRID” do “geom” para 4326 .
Agora salve as configurações do SQL View, e você será redirecionado diretamente para a página de configuração da camada.
Na tela de configuração de camada faça o seguinte:
Na aba “Data”:
– Declare SRS como EPSG:4326
– Gere os Bounding Boxes
Na aba “Tile Cache”:
– Na opção Tile Cache, desmarque a opção “Criar camada de cache para esta camada”
– Clique em “Salvar”
Agora você tem uma camada visível!
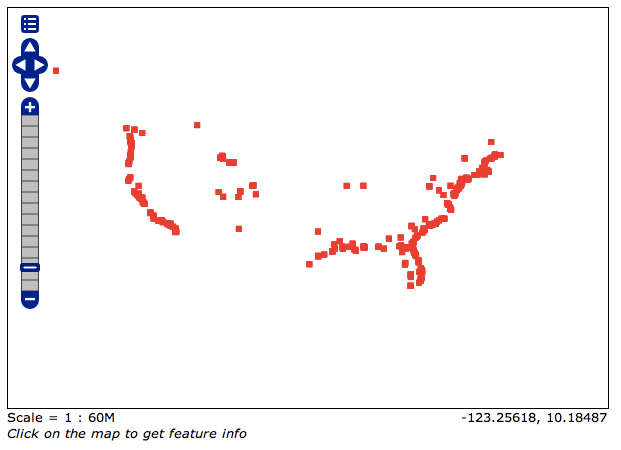
Para testar se a camada funcionou, vamos realizar um teste:
http://localhost:8080/geoserver/wms/reflect?layers=wordmap:geonames&viewparams=word:navajo
Comparando com a imagem acima, é possível verificar que houve uma mudança, mas que é difícil de interpretar sem uma mapa base. No próximo post iremos construir um interface web para que possamos explorar esta camada dinâmica.

