
Os desenvolvedores de código aberto às vezes têm dificuldade em descobrir em qual recurso se concentrar, a fim de gerar o valor máximo para os usuários finais. Como resultado, muitas vezes eles terão desempenho padrão .
Desempenho é o único recurso que todo usuário aprova. O software continuará fazendo as mesmas coisas legais, só que mais rápido.
Para o PostGIS 3.1, houve uma série de melhorias de desempenho que, juntas, podem resultar em um ganho de desempenho substancial para suas cargas de trabalho.
1. Cache de grandes geometrias
As junções espaciais foram eram lentas pela sobrecarga do acesso a grandes geometrias por um longo tempo.
SELECT A.*, B.* FROM A JOIN B ON ST_Intersects(A.geom, B.geom)
Para o SQL acima, o PostgreSQL planejará e executará junções espaciais como essa usando uma “junção de loop aninhada”, o que significa iterar por um lado da junção e testar a condição de junção. Isso resulta em execuções que se parecem com:
- ST_Intersects (A.geom (1), B.geom (1))
- ST_Intersects (A.geom (1), B.geom (2))
- ST_Intersects (A.geom (1), B.geom (3))
Portanto, um lado do teste se repete indefinidamente.
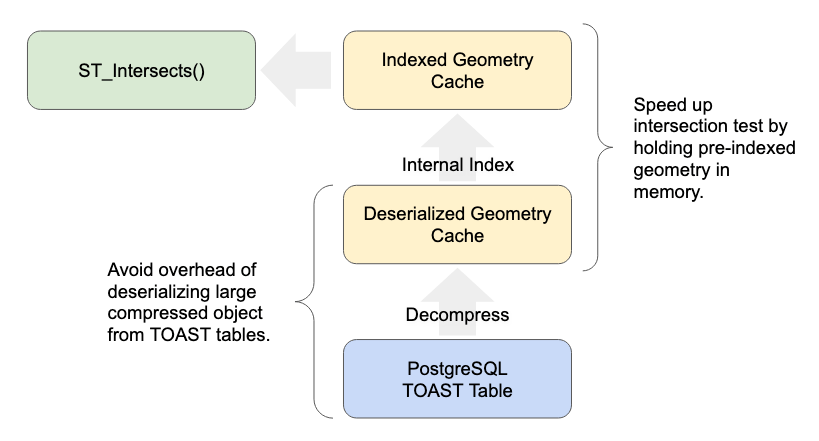
Armazenar esse lado em cache e evitar reler o objeto grande a cada iteração do loop faz uma grande diferença no desempenho. Vimos acelerações 20 vezes maiores em cargas de trabalho de junção espacial comum .
As correções são bastante técnicas, mas se você estiver interessado, tem um artigo do Paul Ramsey detalhado disponível em inglês.
2. Leituras apenas do cabeçalho da geometria
O formato em disco para geometria inclui um cabeçalho curto que possui informações sobre os limites da geometria, o sistema de referência espacial e dimensionalidade. Isso significa que é possível para algumas funções retornar uma resposta depois de ler apenas alguns bytes do cabeçalho, em vez de todo o objeto.
No entanto, nem todas as funções que poderiam fazer uma leitura rápida, era possível fazer uma leitura rápida. Isso agora está resolvido.
3. Geração mais rápida de texto
É muito comum que aplicativos da web e outros gerem formatos de texto dentro do banco de dados, e o código para fazer isso não foi otimizado. A geração de “texto conhecido” (WKT), GeoJSON e saída KML agora usa um caminho mais rápido e evita cópias desnecessárias.
PostGIS agora também usa o mesmo código de número para texto que o PostgreSQL, que se mostrou mais rápido, e também nos permite expor um pouco mais de controle sobre a precisão aos usuários finais.
4. Quão mais rápido?
Para o caso de uso específico de união espacial, aqui está um caso de teste:
1:10 milhões – Limites de país
1:10 milhões – Lugares povoados
Carregue os dados em ambas as versões:
shp2pgsql -D -s 4326 -I ne_10m_admin_0_countries admin | psql postgis30 shp2pgsql -D -s 4326 -I ne_10m_populated_places places | psql postgis30
Execute uma junção espacial que encontre a soma dos locais povoados em cada país.
EXPLAIN ANALYZE SELECT Sum(p.pop_max) as pop_max, a.name FROM admin a JOIN places p ON ST_Intersects(a.geom, p.geom) GROUP BY a.name
Tempo médio em 5 execuções:
- PostGIS 3.0 = 23.4s
- PostGIS 3.1 = 0.9s
Este teste é uma espécie de “pior caso”, em que existem muitos países muito grandes, mas dá uma ideia dos tipos de acelerações que estão disponíveis para junções espaciais contra coleções que incluem maiores (+250 pares de coordenadas) geometrias.
Este post foi escrito originalmente por Paul Ramsey e traduzido e adaptado livremente por este blog.
Fonte: Clever Elephant Blog
